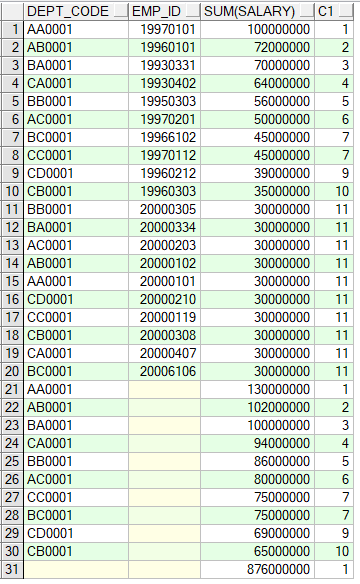
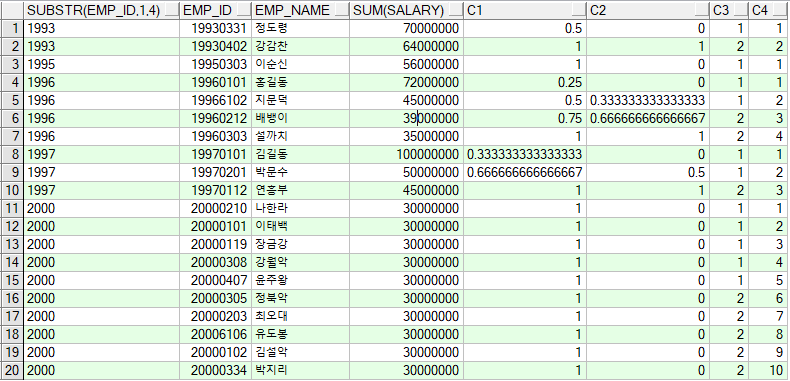
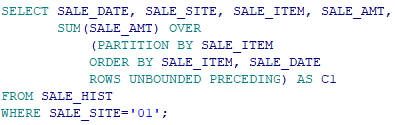
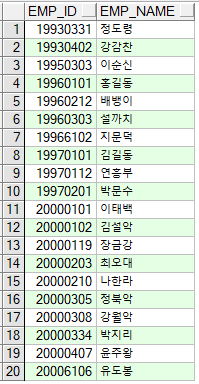
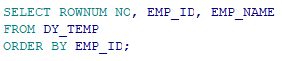
DY_TEMP 테이블
DY_TEMP 테이블
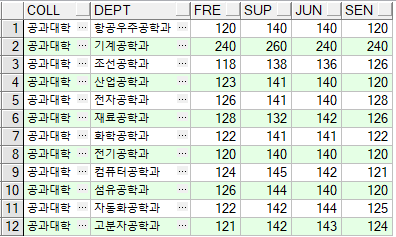
 TDEPT 테이블
TDEPT 테이블
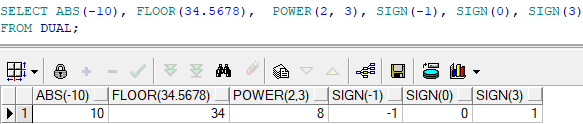
SELECT에서의 산술 연산
<SALARY(연봉)을 이용하여 월 급여 계산>
1) DY_TEMP 테이블에서 SALARY을 이용하여 월 급여를 알아보는 SQL문. 월 급여는 연봉을 18로 나누어 홀수 달에는 연봉의 1/18이 지급되고, 짝수 달에는 연봉의 2/18가 지급된다고 가정했을 대 홀수 달과 짝수 달에받을 금액을 검색

2) 위에서 구한 월 급여에교통비가 10만원씩 지급된다면(짝수 달은 20만원) 위의문장이 어떻게 바뀔지 작성해라.

NULL의 사용
<NULL값인 것을 제외하고 보기>
1) DY_TEMP 테이블에서 HOBBY가 NULL이아닌 사람의 성명을 검색해라.

2) HOBBY가 NULL인 사람은 모두 HOBBY를 "없음"이라고 값을 치환하여 가져오고 나머지는 그대로 값을 읽어온다. (이름과 취미 검색)

3) HOBBY의 값이 NULL인 사원을 '등산'으로 치환했을 때 HOBBY가 '등산'인 사람의 성명을 가져와라.

컬럼 ALIAS와 테이블 ALIAS
1) DY_TEMP의 자료 중 EMP_ID와 EMP_NAME을 각각 '사번', '성명'으로 표시되어 DISPLAY 되도록 COLUMN ALIAS을 부여하여 검색해라.

CONCATENATION
두 개 이상의 문자열을연결하여 하나의 문자열을 만들어 낼 때 사용
방식은 CONCAT함수를 사용하거나 합성연산자(||) 를 이용
1) 성명을 보여줄 때 직급을 괄호 안에 함께 보여주는 경우를 생각해라.

2) 괄호 대신 작은따옴표로 묶어줄 땐 두개를 함께 사용 '(' => '''' 이런 식으로

연산자
<LIKE 검색>
1) 부서 코드가 A로 시작되는 ROW를 검색

2) 부서 코드 중에 A가 들어가는 ROW를 검색

3) 총 6자리 부서코드중 2번째 자리에 A가 들어가는 ROW를 검색

<BETWEEN 검색>
1) 사번이 1997로 시작하는 사원의 사번과 성명을 검색

2) 성명이 'ㄱ'으로 시작되는 사람의 사번과 성명을 검색

GROUP BY와 HAVING
1) LEV별로 최고액 연봉이 얼마인지 검색

2) AREA별로 최소 BOSS_ID를 골라내고 이 결과를 BOSS_ID 별로 정렬

3) 직급별로 연봉 평균을 구한 상태에서 평균 연봉이 5천만원 이상인 경우의 직급과 평균 연봉을 검색

4) 직급별로 사번이제일 늦은 사람을 구하고 그 결과 내에서 사번이 1997로 시작하는 결과를 검색

출처 blog.daum.net/why_i_am/8?category=2113847