5-1. RANKING
RANKING 함수들은 주어진 기준 값에 근거하여 DATASET 내의 다른 RECORD와 비교되는 RECODE의 순서를 계산
5.1.1 RANK와 DENSE_RANK
- RANK() : 중복 순위 개수만큼 다음 순위 값을 증가 시킴
- DENSE_RANK() : 중복 순위가 존재해도 순차적으로 다음 순위 값을 표시
- OVER : 쿼리 RESULT SET을 이용해 동작하는 함수
- PARTITION BY : RESULT SET을 value expression에 지정된 값에 근거하여 분할하는 역할 수행
- ORDER BY : 각 PARTITION 내에서 DATA가 어떤 값을 기준으로 정렬될 것인가를 지정
- NULLS FIRST | NULLS LAST : NULL이 포함된 ROW가 순서상 제일 앞에 위치할 것인지 제일 뒤에 위치할 것인지를 지정
1) SALARY 값으로 순위를 부여하는 SQL 문장
 |
 |
-
RANK와 DENSE_RANK의 차이점은 순위를 부여하는 간격
-
7등이 2명 나오면 다음 등수는 DENSE_RANK : 8등, RANK : 9등이 된다.
-
-
OVER의 의미는 해당 함수가 쿼리의 RESULTEST을 이용하여 동작하는 함수라는 표시
-
()안에 ORDER BY는 RESULTTEST에 순위를 부여할 때의 정렬 기준을 표시
-
2) 직원들을 부서별로 급여 기준 순위를 부여하는 문장 (PARTITION BY 기능)
 |
 |
- PARTITION BY DEPT_CODE에 의해 부서별 급여 RANKING이 구해졌다.
- PARTITION BY는 분석용 함수가 작용하는 단위를 표시(생략될 경우 RESULTSET이 하나의 작용 단위)
3) 사원별 RANKING을 구하고 부서별로 구한 소계까지 RANKING을 부여해라.
 |
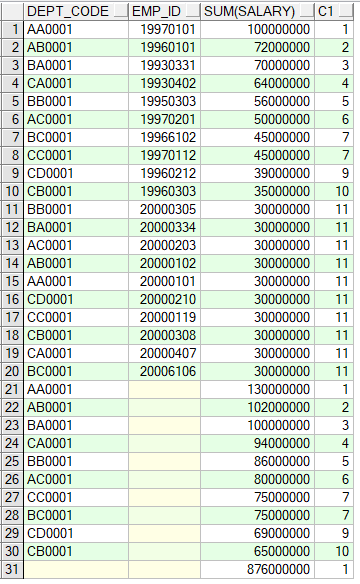 |
- EMP_ID만이 NULL로 나온 ROW는 부서별 SUBTOTAL이고 DEPT_CODE까지 NULL로 나온 것은 GRANDTOTAL(합계)
4) SALE_HIST의 자료를 이용하여 일자별 매출순위와 순위별 사업장, 품목을 보여라.
 |
 |
 |
 |
5.1.2 CUME_DIST, PERCENT_RANK, NTILE(N), ROW_NUMBER()
- CUME_DIST : 관련 DATASET 안에서 해당 ROW의 위치를 0에서 1까지의 값으로 표시해줌
- RANK()와 비슷한 기능이지만 CUME_DIST는 최대값 1을 기준으로 0에서 1사이의 값으로 표시하고 자신과 동일한 순위를 모두 포함한 값을 기준으로 보여줌
- PERCENT_RANK : (자신이 속한 PARTITION내의 자신의 RANK - 1) / (자신이 속한 PARTITION내의 ROW 숫자 - 1)
- NTILE(N) : 자신이 속한 PARTITION의 ROW들을 지정한 숫자만큼으로 분류하고자 할때 각 ROW의 위치를 표시
- ROW_NUMBER() : PARTITION 내의 ROW들에 순서대로 UNIQUE한 일련번호를 부여
1) CUME_DIST와 RANK의 차이점
 |
 |
- C0은 RANKING을 표시
- C1은 CUME_DIST을 표시
- C2는 SALARY를 기준으로 자신과 동일한 값을 포함한 자신의 순위를 표현
2) 각 ROW를 SALARY 기준으로 CUME_DIST, PERCENT_RANK, NTILE(N), ROW_NUMBER()의 값을 구해라.
 |
 |
- C2 : 해당 ROW의 SALARY와 동일한 값과 이전 값의 수 / 20(ROW수)
- C3 : (자신이 속한 PARTITION내의 자신의 RANK - 1) / (자신이 속한 PARTITION내의 ROW 숫자 - 1)
- 이태백) 자신이 속한 PARTITION내의 자신의 RANK - 1 = 1 - 1 = 0
- 자신이 속한 PARTITION내의 ROW 숫자 - 1 = 20 - 1 = 19
- PERCENT_RANK = 0/19 = 0
3) 사번의 앞 4자리를 입사년도라고 가정하고 동일 입사년도 내에서 각 ROW가 가지는 SALARY순의 값을 구해라.
 |
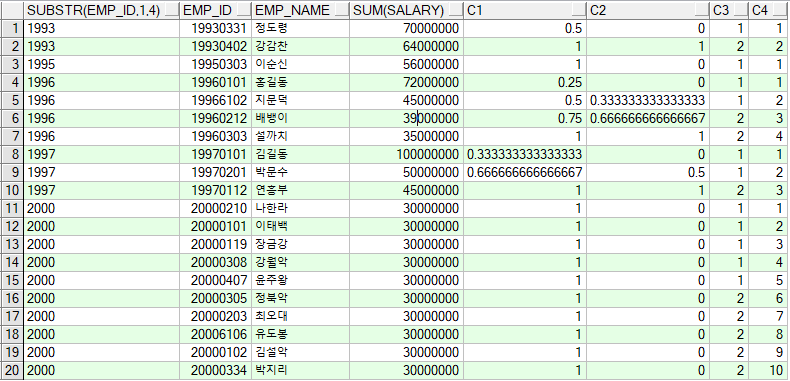 |
5-2. WINDOWING 함수
- OVER : 쿼리 RESULT SET을 이용해 동작하는 함수라는 구분
- RESULT : SET을 value expression2에 지정된 값에 근거하여 분할하는 역할 수행
- ORDER BY : 각 PARTITION 내에서 DATA가 어떤 값을 기준으로 정렬될 것인가를 지정
- NULLS FIRST | NULL LAST : NULL이 포함된 ROW가 순서상 제일 앞에 위치할 것인지 뒤에 위치할 것인지를 지정
- ROWS | RANGE : 자료의 물리적 순서를 이용(ROWS)할 것인지 논리적 순서를 이용(RANGE)할 것인지를 결정
- BETWEEN... AND : 자료의 범위를 결정
- UNBOUNDED PRECEDING : 지정된 값 이전의 모든 ROW를 포함시킴
- UNBOUNDED FOLLOWING : 지정된 값 이후의 모든 ROW를 포함시킴
- CURRENT ROW : 현재 ROQ를 시작 값 또는 마지막 값으로 이용할 때 사용함
1) SALE_HIST테이블에서 '01' 사업장의 품목별 당일 판매액과 당일까지의 누적 판매액을 구해라.
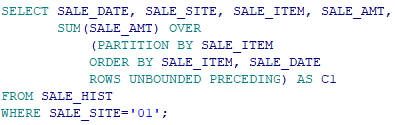 |
 |
2) 일자별 사업장별 매출액과 사업장별 매출액의 3일 이동평균을 구해라.
 |
3) 자신의 급여와 바로 이전 사번 3명의 급여를 이용하여 합계, COUNT, 평균을 구해라.
 |
 |
4) 각 ROW의 판매액, 동일 일자/동일 품목의 최대 판매액, 최대 판매액 사업장, 해당 사업장 최소 판매액, 최소 판매액 사업장을 구해라.
 |
 |
- FIRST_VALUE : PARTITION BY에 의해 분류된 범위 내에서 ORDER BY에 의해 정렬을 한 후 ROWS 또는 RANGE에 의해 범위가 지정되면 그 중 제일 앞에 위치하는 ROW의 값들을 읽어올 때 사용
- LAST_VALUE : PARTITION BY에 의해 분류된 범위 내에서 ORDER BY에 의해 정렬을 한 후 ROWS 또는 RANGE에 의해 범위가 지정되면 그 중 제일 뒤에 위치하는 ROW의 값들을 읽어올 때 사용
5) 일자별 매출액과 함께 각 일자의 매출액이 전체일자 매출액에서 차지하는 비율을 구해라.
 |
 |
- RATIO_TO_REPORT : 전체 대비 해당 ROW의 값이 차지하는 비율을 구하는 함수
6) 사업장별 품목의매출액과 함께 동일 사업장 동일 품목의 전일 매출액과 다음날 매출액을 구해라.
 |
 |
- LAG : 바로 이전 값을 참조, LEAD : 바로 이후 값을 참조
- LAG와 LEAD 함수 안에 지정되는 숫자가 각각 앞뒤로 몇 번째 ROW를 참조할 것인지를 결정
5-2-1) SALE_HIST 자료를 이용하여 '01' 사업장 'PENCIL' 품목의 일자별 누적 판매금액을 구해라.
 |
 |
5-2-2) 품목별/일자별로 과거 판매액을 모두 이용하는 이동 평균값을 구하라.
 |
 |
5-2-3) '01' 사업장 'PENCIL' 품목에 대해 일자별 매출액과 전일 매출, 당일과 전일의 매출액 차이를 구하시오.
 |
 |
5-3. CASE
1) SALARY로 분류하여 30000000이하는 'D', 30000000 초과 50000000 이하는 'C', 50000000 초과 70000000 이하는 'B', 70000000 초과는 'A' 라고 등급을 분류하여 등급별 인원수를 구해라.
 |
 |
2) 행 단위로 나오는 값을 컬럼 단위로 표현해라.
 |
 |
5-3-1) 일자별 품목별로 '01', '02' 사업장 판매 금액 합, '02', '03' 사업장 판매 금액 합을 구해라.
 |
 |
5-4. 통계 함수
- VAR_POP : 모집단의 분산을 구해줌
- AVR_SAMP : 표본집단의 분산을 구해줌
- STDDEV_POP : 모집단의 표준편차를 구해줌
- SDTDEV_SAMP : 표본집단의 표준편차를 구해줌
- CORVAR_POP : 모집단의 공 분산을 구해줌
- CORVAR_SAMP : 표본집단의 공 분산을 구해줌
- CORR : 산관계수를 구해줌
5-5. 회귀 분석용 함수
- REGR_COUNT : 회귀선상에 찍히는 값을의 숫자를 구해줌
- REGR_AVGY, REGR_AVGX : 회귀선의 독립변수와 종속 변수의 평균을 구해줌
- ...
'BOOK > IT' 카테고리의 다른 글
| PART 14. 가상 테이블 뷰 (0) | 2021.02.24 |
|---|---|
| PART 08. 서브쿼리 (0) | 2021.02.23 |
| PART 07. 조인 (0) | 2021.02.23 |
| PART 05. SQL 주요 함수 (0) | 2021.02.23 |
| [오라클 실습] 1장 자료의 조회 (0) | 2021.02.19 |