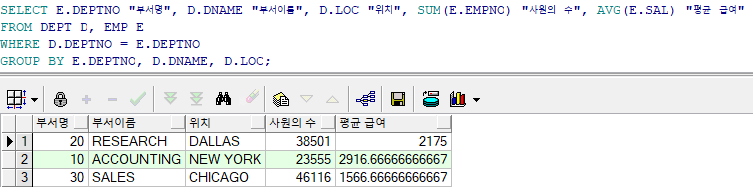
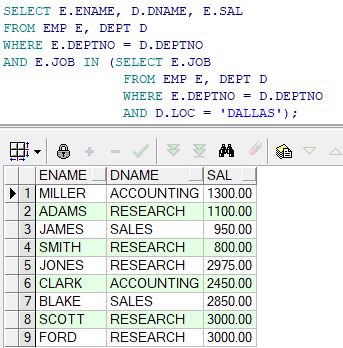
Unique Key를 생성하는 방법은 DBMS마다 차이가 있다.
MS-SQL은 IDENTITY를, MySQL은 auto_increment,
오라클에서는 Sequence를 사용하여 다음과 같이 유사하게 구현할 수 있다.
1. 자동증가컬럼을 사용하고자 하는 MYTABLE테이블을 생성한다.
CREATE TABLE MYTABLE(
ID NUMBER, NAME VARCHAR2(20)
);
2. CREATE SEQUENCE 라는 문장을 사용하여 SEQ_ID라는 이름의 시퀀스를 만든다.
CREATE SEQUENCE SEQ_ID INCREMENT BY 1 START WITH 10000;
-- INCREMENT BY 1 : 증가값은 1
-- START WITH 10000 : 10000부터 증가
3. 테이블에 데이터 입력시에는 NEXTVAL이라는 슈도 컬럼(Pseudo-column)을 이용하여 시퀸스를 사용한다.
INSERT INTO MYTABLE VALUES( SEQ_ID.NEXTVAL, '홍길동');
-- CURRVAL : 현재 값을 반환 합니다. .
-- NEXTVAL : 현재 시퀀스값의 다음 값을 반환 합니다.
Sequence 구문
CREATE SEQUENCE sequence_name
[START WITH n]
[INCREMENT BY n]
[MAXVALUE n | NOMAXVALUE]
[MINVALUE n | NOMINVALUE]
[CYCLE | NOCYCLE]
* START WITH
시퀀스의 시작 값을 지정합니다. n을 1로 지정하면 1부터 순차적으로 시퀀스번호가 증가 합니다.
* INCREMENT BY
시퀀스의 증가 값을 말합니다. n을 2로 하면 2씩 증가합니다.
START WITH를 1로 하고 INCREMENT BY를 2으로 하면 1, 3, 5,7,..
이렇게 시퀀스 번호가 증가하게 됩니다.
* MAXVALUE n | NOMAXVALUE
MAXVALUE는 시퀀스가 증가할수 있는 최대값을 말합니다.
NOMAXVALUE는 시퀀스의 값을 무한대로 지정합니다.
* MINVALUE n | NOMINVALUE
MINVALUE는 시퀀스의 최소값을 지정 합니다.
기본값은 1이며, NOMINVALUE를 지정할 경우 최소값은 무한대가 됩니다
[사용규칙]
* NEXTVAL, CURRVAL을 사용할 수 있는 경우
- subquery가 아닌 select문
- insert문의 select절
- insert문의 value절
- update문의 set절
* NEXTVAL, CURRVAL을 사용할 수 없는 경우
- view의 select절
- distinct 키워드가 있는 select문
- group by, having, order by절이 있는 select문
- select, delete, update의 subquery
- create table, alter table 명령의 default값
[수정]
ALTER SEQUENCE sequence_name
[INCREMENT BY n]
[MAXVALUE n | NOMAXVALUE]
[MINVALUE n | NOMINVALUE]
[CYCLE | NOCYCLE]START WITH는 수정할수 없습니다.
START WITH 절이 없다는 점을 빼고는 CREATE SEQUENCE와 같습니다.
[삭제]
DROP SEQUENCE sequence_name
'프로그램 > DataBase' 카테고리의 다른 글
| [Oracle : ERROR] ORA-12154: TNS:지정된 접속 식별자를 분석할 수 없음 (0) | 2021.03.09 |
|---|---|
| [Oracle] Delete, Truncate, Drop 비교 (0) | 2021.03.05 |
| [PL/SQL Developer] 뷰(VIEW) 실습 (0) | 2021.02.18 |
| [PL/SQL Developer] 함수 실습 (0) | 2021.02.18 |
| [Oracle] SQL 쿼리문 예제 50문제 (0) | 2021.02.16 |